はじめに
これは2021年振り返りカレンダーの3日目の記事です.
前回はGCP+ネイティブアプリの構成でGitLab flowを構築するという内容でした.
ネイティブアプリと言ってるくせにそこのCD周りは完全に省略するという半詐欺行為を行って しまいましたが,今回はそれについて書きます.
代表的なネイティブアプリ用のCI/CDツールとしては以下のようなものがあります.
- Bitrise
- Fastlane
- CodeMagic
他にも,汎用CI/CDプラットフォームのMacインスタンスを提供しているものを 利用することも考えられます.
今回は,採用例や情報が多くreact-native (expo) のビルドも簡単にできそうなBitriseを使用することにしました (調べていた時はFastlaneを知らなかったのですが,お金あんまり使いたくなかったので, 知ってたらFastlane使ってたかもです.Bitriseも無料枠があるのですが, 時間制限がキツかったのでOrgにしたら1万ぐらいしてビビりました.).
仕様
今回はreact-native (expo) で開発しているアプリのiOSビルドを行います.
また,環境はstgとprdの2つあり,ビルド対象は以下のパターンがあるとします.
- devアプリを配布用にビルド
- devアプリをOTA(今回は省略)
- prdアプリをAppStore審査に提出
- prdアプリをOTA(今回は省略)
これらを前回作ったGitLab flowに組み込みます.
devアプリの配布ビルドは新たなバージョンリリースを行なった際に自動で走り, prdアプリの審査ビルドはprd環境にリリースPRがマージされた時に行われるとします.
実装
Bitriseには,yamlとかからワークフローを作るモードとUI上でワークフローを組む方法がありますが, 今回は直感的にできるUIでの構築を行います.
アプリケーションとワークフローの作成
Bitriseでは,まずアプリケーションを作り,その下にビルドのワークフローを作るという流れになっています.
作り方は以下を参照.
ここでは,環境ごとにアプリを作成し(serviceというアプリに対して,service_stgとservice_prd), その下にビルドワークフローを作ることとします. 以下のような感じです.
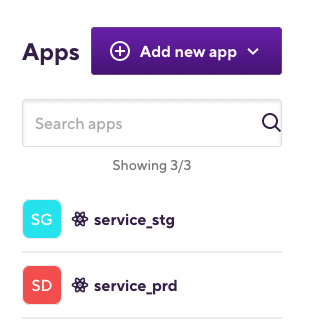
次に,各アプリの下に必要なワークフローを定義します. stgにはdeploy_distributeとdeploy_otaを,prdにはdeploy_storeとdeploy_otaを作成します.
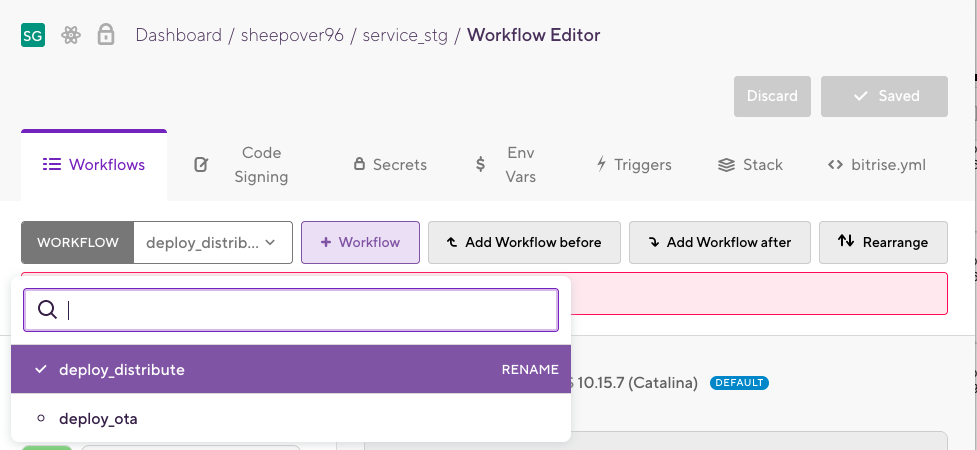
stgアプリの配信ワークフローの構築(service_devのdeploy_distribute)
このワークフローでは,チームの人全員が新機能などの動作確認ができるように, stgアプリのビルドとその成果物の配布を行います. ワークフローの全体像は以下のような感じになっています.

半年ぐらい前に作ったのでdeprecatedになってる箇所もありますが, 各要素について説明していきます.
Activate SSH key
まず,最初のActivate SSH keyではGitHubからpullするためにssh keyの確認を行なっています. ssh keyの設定についてはアプリケーションのsettingsから変更でき, 以下の3つ設定方法があります.
SSHキーペアの自動追加:Bitriseは公開SSHキーをGitリポジトリに自動的に登録します。リポジトリに対する管理者権限がある場合は、これを選択してください。
SSHキーペアを生成する:BitriseはSSHキーペアを生成するため、Gitリポジトリに公開キーを手動で登録する必要があります。
独自のSSHキーペアを使用する:認証用に独自のSSHキーペアを提供し、公開キーをGitリポジトリに手動で登録する必要があります。
自分はレポジトリ連携時に自動で登録されたものを使っていました(というかあんまり意識してなかった).
Git Clone Repository
次のGit Clone Repositoryは,名前の通りレポジトリのクローンを行います.
Do anything with Script step
次のDo anything with Script stepは,任意のbash scriptを実行できるものです. 今回はビルドをトリガーしたバージョンタグを読み取り,expoの設定ファイルの バージョン部分を上書きするのに使いました(ステップの名前はちゃんと変えたほうがいいと思う).
実行するスクリプトの内容は以下のような感じです.
VERSION=`echo $BITRISE_GIT_TAG | sed -e "s/v//"` envman add --key BUNDLE_VERSION_STRING --value $VERSION APP_JSON=`jq ".expo.version=\"$VERSION\" | .expo.ios.bundleIdentifier=\"$BUNDLE_ID\"" ui/app.json` echo $APP_JSON > ui/app.json
bitriseには,ワークフロー全体で参照できる環境変数がいくつか定義されており,BITRISE_GIT_TAGには ビルドをトリガーしたタグが入っています. 今回はそこからバージョンを読み取り,expoの設定ファイルであるapp.jsonへ書き込みを行なっています. これにより,リリース時に手動で設定ファイル中のバージョンをあげる作業をなくすことができます.
Run yarn command, Run cocoaPods install
ここ2つでは,yarnによるパッケージのインストール,cocoaPodsによるモジュール?のインストールを 行なっています.
時間がかかる場合はこちらの前後でキャッシュ処理を挟むこともできます.
devcenter.bitrise.io qiita.com
iOS Auto Provision with App Store Connect API
(注)現在はdeprecatedになっている模様.Xcodeビルドのステップと合体したらしい.
こちらでは,アプリのProvision Profileファイルの生成を行います.
Provision Profileの詳細については以下など.
通常はProvisionファイルはAppStore Connectで作る必要がありますが,Bitriseでは その自動生成を行ってくれます.
stgでは配布用アプリのビルドを行うので,Distribution Typeの設定をad-hocにします.
そして,BitriseがAppStore Connectへ接続できるようにするため,App Store Connect API key をBitriseに登録しておきます. 以下が参考になります.Appleアカウントでの連携も可能ですが,定期的に連携が切れるため,API keyを使うのが 推奨されています.
また,事前にAppStore Connect上で配布先デバイスの登録を行っておきます. 以下が参考になります.
https://softmoco.com/devenv/how-to-register-devices-apple-developer.php
Xcode Archive & Export for iOS
ここではビルドを行います.配布用ビルドなので,Distribution methodをad-hocにしておきます. また,環境ごとにschemeを避けている場合は,それも設定します.
Deploy to Bitrise.io
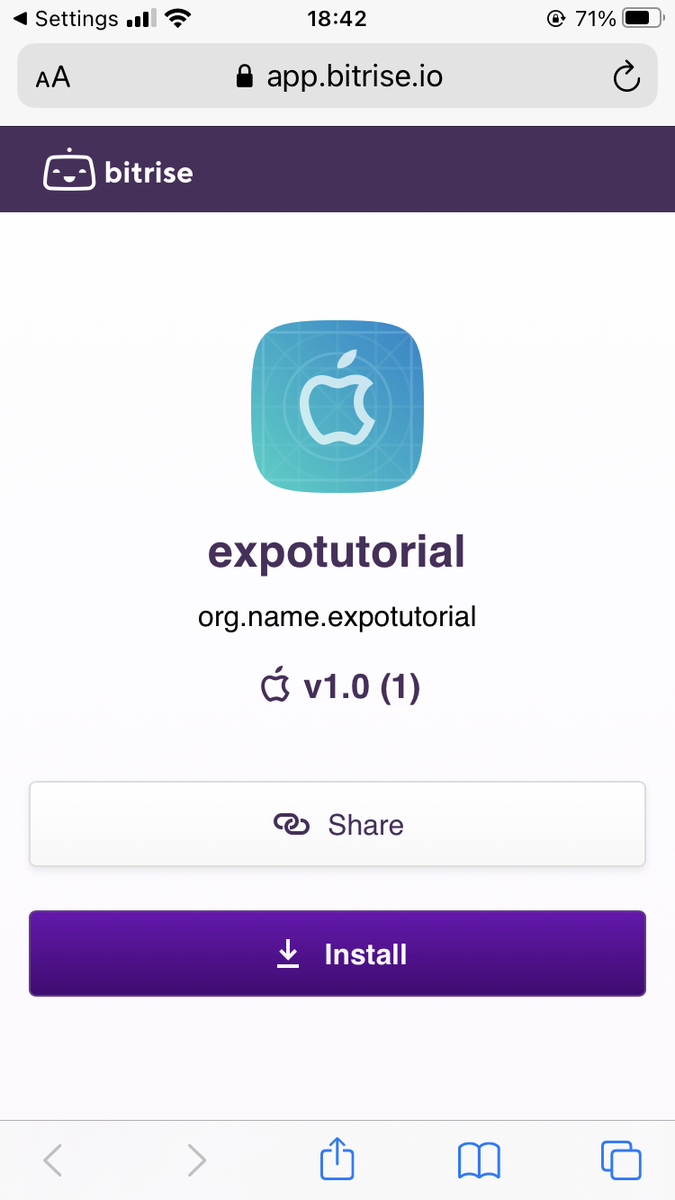
ここでは,前のステップで生成されたipaファイルを,Bitriseの配信サーバへデプロイし, チームの人がWebページからダウンロードできるようにします.
ページの見た目は以下のような感じになっています(めんどかったのでアプリの名前やIDは適当です).
Send a Slack message
ビルドの結果をslackに通知します.
パラメータとしてはslackのoauth tokenと通知先のチャンネルが必要です.
oauth tokenはBitriseのシークレットに保存しておき,それを参照します.
これで一旦,stgアプリの配信用ワークフローが完成です.
prdアプリの審査提出ワークフローの構築(service_prdのdeploy_store)
審査提出ワークフローの全体像は以下のような感じです.
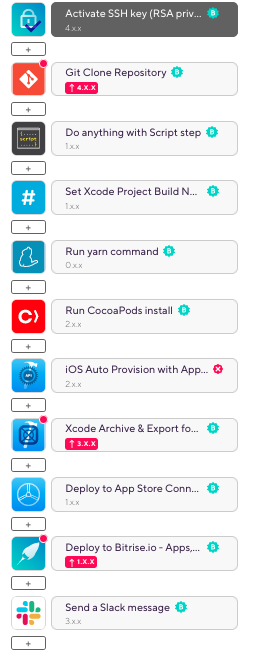
大体の部分はstgの配信ワークフローと同じですが,違う部分について書いていきます.
Set Xcode Project Build Number
あるバージョンのアプリをストア審査に出した時,それにバグがあり,同じバージョンでもう一度出し直したい というケースや,アプリがどのビルドで提出されたかを特定したいというケースがあると思います.
iOSアプリではバージョンとは別にビルド番号を持っており,毎回のビルドで別の値をセットすることで, 上記の要件を満たすことができます. 以下が詳しいです.
Bitriseではワークフローの実行ごとにインクリメントされるBuildNumberを持っているため, このステップではその値を設定しています.
iOS Auto Provision with App Store Connect API
stg配信の時はad-hocにしましたが,app-storeにします.
Xcode Archive & Export for iOS
stg配信の時はad-hocにしましたが,app-storeにします.
Deploy to App Store Connect
ipaファイルをAppStore Connectにアップロードしてくれます.
アカウント名とパスワードをシークレットに入れ,設定します. また,二段階認証を有効にしてる場合はApplication-specific-passwordも設定します.
App 用パスワードを使う - Apple サポート (日本)
記事の一番最後に一応ワークフロー全体のyamlもはっておこうと思います.
ワークフローのトリガーと既存のCI/CD flowとの連携
Bitriseでは,連携したGitHubレポジトリへのpush,pull request,tag pushに応じたトリガー を設定することが可能です.
また,各アプリケーションには以下のようにビルドを開始するためのURLが発行されるため, それを用いて既存のCI/CDと連携することも可能です.GitHub Actionsなどの上で用いれば, コードとして管理できるため,便利だと思います.
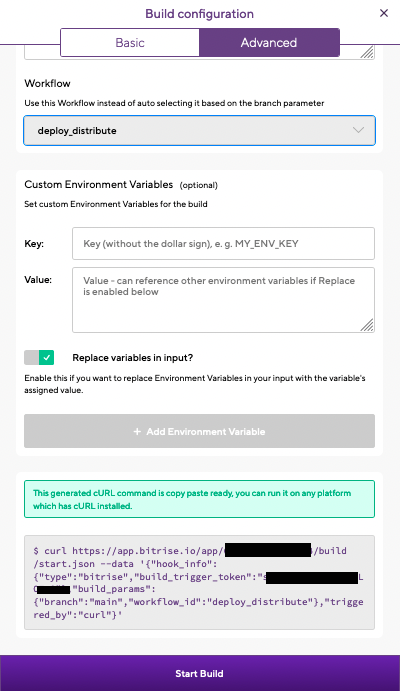
自分は以下のようなstore審査開始コマンドを作ってローカルやGitHub Actionsから使っていました.
#!/bin/bash function deploy_ui_distribute() { TAG_NAME=$2 command="curl https://app.bitrise.io/app/hogehogehoge/build/start.json --data '{\"hook_info\":{\"type\":\"bitrise\",\"build_trigger_token\":\"hogehogehoge\"},\"build_params\":{\"branch\":\"production\",\"workflow_id\":\"deploy_store\",\"tag\":\"${TAG_NAME}\"},\"triggered_by\":\"curl\"}'" eval $command } $1 $@
productionブランチにリリースPRマージされたときに審査ビルドするGitHub Actions
on:
pull_request:
branches:
- production
types: [closed]
jobs:
deploy_prd:
runs-on: ubuntu-latest
if: github.event.pull_request.merged == true && contains(github.head_ref, 'release')
steps:
- uses: actions/checkout@v2
- name: Deploy UI to Store
id: deploy_store
working-directory: ./release/prd
run: |
bash deploy.sh deploy_ui_store `echo ${{ github.head_ref }} | sed -e "s/release\///"`
その他細かい知見など
- ビルドに90分ぐらいかかることもあり,プランの制限を超えて落ちることもあった.もう一回ビルドすると成功したりする.Xcode Archiveがやっぱ遅いので,そこの最適化周りは勉強したいかも.
- ビルドステップは必要に応じて自分で作ることもできる(欲しいパラメータあったのでリクエスト送ったら開発チームに伝えとくけど自分でも作れるよと返信をくれました).
- ワークフローをコードで管理したい感あるが,GitHubと連携させると,WebUIじゃなくなるぽい?のでどうするのがいいんだろう.
最後に
去年行ったBitriseでreact-nativeアプリのCI/CD構築について書きました.ネイティブアプリ初めてかつ,一人でCI/CD構築をしたので とりあえずビルドできればいいやなテキトーな部分が多く, 使えてない機能とかも多いのですが,UIで直感的にワークフローを組めるのは すごく便利でした(パラメータもいい感じに設定してあるし,ドキュメントも豊富). ビルド時間が結構シビアで,お金払わないときつかったりもするのですが,そこら辺 クリアできるならばまた勉強して使ってみたいと思います. あとFastlaneも勉強してみます.
以下,Bitrise ワークフローのyamlです.貼り付ければそのまま再現できます.
--- format_version: '8' default_step_lib_source: https://github.com/bitrise-io/bitrise-steplib.git project_type: react-native workflows: deploy_distribute: steps: - cache-pull@2: {} - activate-ssh-key@4: run_if: '{{getenv "SSH_RSA_PRIVATE_KEY" | ne ""}}' - git-clone@4: {} - script@1: title: Do anything with Script step inputs: - content: |- #!/usr/bin/env bash # fail if any commands fails set -e # debug log set -x # set env vars cp ui/.env.prd ui/.env # set release version VERSION=`echo $BITRISE_GIT_TAG | sed -e "s/v//"` envman add --key BUNDLE_VERSION_STRING --value $VERSION APP_JSON=`jq ".expo.version=\"$VERSION\" | .expo.ios.bundleIdentifier=\"$BUNDLE_ID\"" ui/app.json` echo $APP_JSON > ui/app.json - yarn@0: inputs: - workdir: ui - command: install - set-xcode-build-number@1: inputs: - plist_path: ui/ios/service/info.plist - cocoapods-install@2: {} - ios-auto-provision-appstoreconnect@2: inputs: - distribution_type: app-store - xcode-archive@3: inputs: - export_method: app-store - deploy-to-bitrise-io@1: {} - slack@3: inputs: - text: "*$BUNDLE_VERSION_STRING* です" - api_token: "$SLACK_OAUTH_TOKEN" - channel: "$SLACK_NOTIFICATION_CHANNEL" - webhook_url: "$SLACK_WEBHOOK_URL" - cache-push@2: {} description: For stg distribution deploy_ota: steps: - cache-pull@2: {} - activate-ssh-key@4: run_if: '{{getenv "SSH_RSA_PRIVATE_KEY" | ne ""}}' - git-clone@4: {} - yarn@0: inputs: - workdir: ui - command: install - cocoapods-install@2: {} - script@1: inputs: - content: |- #!/usr/bin/env bash # fail if any commands fails set -e # debug log set -x # set release version VERSION=`echo $BITRISE_GIT_TAG | sed -e "s/v//"` envman add --key BUNDLE_VERSION_STRING --value $VERSION APP_JSON=`jq ".expo.version=\"$VERSION\"" ui/app.json` echo $APP_JSON > ui/app.json title: set version numbers - set-xcode-build-number@1: inputs: - build_short_version_string: "$BUNDLE_VERSION_STRING" - plist_path: ui/ios/service/Info.plist - script@1: title: expo publish inputs: - content: |- #!/usr/bin/env bash # fail if any commands fails set -e # debug log set -x # expo publish npm install -g expo-cli expo login -u $EXPO_USERNAME -p $EXPO_PASSWORD cd ui cp .env.prd .env expo publish --release-channel prd - slack@3: inputs: - text: "$BUNDLE_VERSION_STRING" - api_token: "$SLACK_OAUTH_TOKEN" - channel: "$SLACK_NOTIFICATION_CHANNEL" - webhook_url: '' - cache-push@2: {} description: For stg distribution deploy_store: steps: - cache-pull@2: {} - activate-ssh-key@4: run_if: '{{getenv "SSH_RSA_PRIVATE_KEY" | ne ""}}' - git-clone@4: {} - script@1: title: Do anything with Script step inputs: - content: |- #!/usr/bin/env bash # fail if any commands fails set -e # debug log set -x # set env vars cp ui/.env.prd ui/.env # set release version VERSION=`echo $BITRISE_GIT_TAG | sed -e "s/v//"` envman add --key BUNDLE_VERSION_STRING --value $VERSION APP_JSON=`jq ".expo.version=\"$VERSION\" | .expo.ios.bundleIdentifier=\"$BUNDLE_ID\"" ui/app.json` echo $APP_JSON > ui/app.json - set-xcode-build-number@1: inputs: - build_short_version_string: "$BUNDLE_VERSION_STRING" - plist_path: ui/ios/service/Info.plist - yarn@0: inputs: - workdir: ui - command: install - cocoapods-install@2: {} - ios-auto-provision-appstoreconnect@2: inputs: - distribution_type: app-store - xcode-archive@3: inputs: - compile_bitcode: 'no' - upload_bitcode: 'no' - export_method: app-store - deploy-to-itunesconnect-application-loader@1: inputs: - itunescon_user: "$APPLE_ID_EMAIL" - password: "$APPLE_ID_PASSWORD" - app_password: "$APPLE_APP_PASSWORD" - connection: 'off' - deploy-to-bitrise-io@1: {} - slack@3: inputs: - text: "$BUNDLE_VERSION_STRING" - api_token: "$SLACK_OAUTH_TOKEN" - channel: "$SLACK_NOTIFICATION_CHANNEL" - webhook_url: '' - cache-push@2: {} description: For stg distribution app: envs: - opts: is_expand: false PROJECT_LOCATION: ui/android - opts: is_expand: false MODULE: ui - opts: is_expand: false VARIANT: '' - opts: is_expand: false BITRISE_PROJECT_PATH: ui/ios/service.xcworkspace - opts: is_expand: false BITRISE_SCHEME: service_prd - opts: is_expand: false BITRISE_EXPORT_METHOD: develop - opts: is_expand: false EXPO_USERNAME: service-dev - opts: is_expand: false BUNDLE_ID: com.service.service - opts: is_expand: false SLACK_NOTIFICATION_CHANNEL: "#service_notice_bitrise"








